Russell Coker: Dell PowerEdge T320 and Linux
I recently bought a couple of PowerEdge T320 servers, so now to learn about setting them up. They are a little newer than the R710 I recently setup (which had iDRAC version 6), they have iDRAC version 7.
RAM Speed
One system has a E5-2440 CPU with 2*16G DDR3 DIMMs and a Memtest86+ speed of 13,043MB/s, the other is essentially identical but with a E5-2430 CPU and 4*16G DDR3 DIMMs and a Memtest86+ speed of 8,270MB/s. I had expected that more DIMMs means better RAM performance but this isn t what happened. I firstly upgraded the BIOS, as I expected it didn t make a difference but it s a good thing to try first.
On the E5-2430 I tried removing a DIMM after it was pointed out on Facebook that the CPU has 3 memory channels (here s a link to a great site with information on that CPU and many others [1]). When I did that I was prompted to disable advanced ECC (which treats pairs of DIMMs as a single unit for ECC allowing correcting more than 1 bit errors) and I had to move the 3 remaining DIMMS to different slots. That improved the performance to 13,497MB/s. I then put the spare DIMM into the E5-2440 system and the performance increased to 13,793MB/s, when I installed 4 DIMMs in the E5-2440 system the performance remained at 13,793MB/s and the E5-2430 went down to 12,643MB/s.
This is a good result for me, I now have the most RAM and fastest RAM configuration in the system with the fastest CPU. I ll sell the other one to someone who doesn t need so much RAM or performance (it will be really good for a small office mail server and NAS).
Firmware Update
BIOS
The first issue is updating the BIOS, unfortunately the first link I found to the Dell web site didn t have a link to download the Linux installer. It offered a Windows binary, an EFI program, and a DOS binary. I m not about to install Windows if there is any other option and EFI is somewhat annoying, so that leaves DOS. The first Google result for installing FreeDOS advised using unetbootin , that didn t work at all for me (created a USB image that the Dell BIOS didn t recognise as bootable) and even if it did it wouldn t have been a good solution.
I went to the FreeDOS download page [2] and got the Lite USB zip file. That contained FD12LITE.img which I could just dd to a USB stick. I then used fdisk to create a second 32MB partition, used mkfs.fat to format it, and then copied the BIOS image file to it. I booted the USB stick and then ran the BIOS update program from drive D:. After the BIOS update this became the first system I ve seen get a totally green result from spectre-meltdown-checker !
I found the link to the Linux installer for the new Dell BIOS afterwards, but it was still good to play with FreeDOS.
PERC Driver
I probably didn t really need to update the PERC (PowerEdge Raid Controller) firmware as I m just going to run it in JBOD mode. But it was easy to do, a simple bash shell script to update it.
Here are the perccli commands needed to access disks, it s all hot-plug so you can insert disks and do all this without a reboot:
# show overview perccli show # show controller 0 details perccli /c0 show all # show controller 0 info with less detail perccli /c0 show # clear all "foreign" RAID members perccli /c0 /fall delete # add a vd (RAID) of level RAID0 (r0) with the drive 32:0 (enclosure:slot from above command) perccli /c0 add vd r0 drives=32:0The perccli /c0 show command gives the following summary of disk ( PD in perccli terminology) information amongst other information. The EID is the enclosure, Slt is the slot (IE the bay you plug the disk into) and the DID is the disk identifier (not sure what happens if you have multiple enclosures). The allocation of device names (sda, sdb, etc) will be in order of EID:Slt or DID at boot time, and any drives added at run time will get the next letters available.
---------------------------------------------------------------------------------- EID:Slt DID State DG Size Intf Med SED PI SeSz Model Sp ---------------------------------------------------------------------------------- 32:0 0 Onln 0 465.25 GB SATA SSD Y N 512B Samsung SSD 850 EVO 500GB U 32:1 1 Onln 1 465.25 GB SATA SSD Y N 512B Samsung SSD 850 EVO 500GB U 32:3 3 Onln 2 3.637 TB SATA HDD N N 512B ST4000DM000-1F2168 U 32:4 4 Onln 3 3.637 TB SATA HDD N N 512B WDC WD40EURX-64WRWY0 U 32:5 5 Onln 5 278.875 GB SAS HDD Y N 512B ST300MM0026 U 32:6 6 Onln 6 558.375 GB SAS HDD N N 512B AL13SXL600N U 32:7 7 Onln 4 3.637 TB SATA HDD N N 512B ST4000DM000-1F2168 U ----------------------------------------------------------------------------------The PERC controller is a MegaRAID with possibly some minor changes, there are reports of Linux MegaRAID management utilities working on it for similar functionality to perccli. The version of MegaRAID utilities I tried didn t work on my PERC hardware. The smartctl utility works on those disks if you tell it you have a MegaRAID controller (so obviously there s enough similarity that some MegaRAID utilities will work). Here are example smartctl commands for the first and last disks on my system. Note that the disk device node doesn t matter as all device nodes associated with the PERC/MegaRAID are equal for smartctl.
# get model number etc on DID 0 (Samsung SSD) smartctl -d megaraid,0 -i /dev/sda # get all the basic information on DID 0 smartctl -d megaraid,0 -a /dev/sda # get model number etc on DID 7 (Seagate 4TB disk) smartctl -d megaraid,7 -i /dev/sda # exactly the same output as the previous command smartctl -d megaraid,7 -i /dev/sdcI have uploaded etbemon version 1.3.5-6 to Debian which has support for monitoring smartctl status of MegaRAID devices and NVMe devices. IDRAC To update IDRAC on Linux there s a bash script with the firmware in the same file (binary stuff at the end of a shell script). To make things a little more exciting the script insists that rpm be available (running apt install rpm fixes that for a Debian system). It also creates and runs other shell scripts which start with #!/bin/sh but depend on bash syntax. So I had to make /bin/sh a symlink to /bin/bash. You know you need this if you see errors like typeset: not found and [: -eq: unexpected operator and then the system reboots. Dell people, please test your scripts on dash (the Debian /bin/sh) or just specify #!/bin/bash. If the IDRAC update works it will take about 8 minutes. Lifecycle Controller The Lifecycle Controller is apparently for installing OS and firmware updates. I use Linux tools to update Linux and I generally don t plan to update the firmware after deployment (although I could do so from Linux if needed). So it doesn t seem to offer anything useful to me. Setting Up IDRAC For extra excitement I decided to try to setup IDRAC from the Linux command-line. To install the RAC setup tool you run apt install srvadmin-idracadm7 libargtable2-0 (because srvadmin-idracadm7 doesn t have the right dependencies).
# srvadmin-idracadm7 is missing a dependency apt install srvadmin-idracadm7 libargtable2-0 # set the IP address, netmask, and gatewat for IDRAC idracadm7 setniccfg -s 192.168.0.2 255.255.255.0 192.168.0.1 # put my name on the front panel LCD idracadm7 set System.LCD.UserDefinedString "Russell Coker"Conclusion This is a very nice deskside workstation/server. It s extremely quiet with hardly any fan noise and the case is strong enough to contain the noise of hard drives. When running with 3* 3.5 SATA disks and 2*10k 2.5 SAS disks on a wooden floor it wasn t annoyingly loud. Without the SAS disks it was as quiet as you can expect any PC to be, definitely not the volume you expect from a serious server! I bought the T320 systems loaded with SAS disks which made them quite loud, I immediately put the disks on ebay and installed SATA SSDs and hard drives which gives me more performance and more space than the SAS disks with less cost and almost no noise. 8*3.5 drive bays gives room for expansion. I currently have 2*SATA SSDs and 3*SATA disks, the SSDs are for the root filesystem (including /home) and the disks are for a separate filesystem for large files.
 The still recent-ish
The still recent-ish  Wrote a timezone checker page.
Wrote a timezone checker page.
 There are ton of articles out there to configure mutt and all related
things to it. But I find certain configs very hard to get. So I will
write down those.
There are ton of articles out there to configure mutt and all related
things to it. But I find certain configs very hard to get. So I will
write down those.

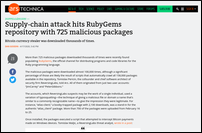






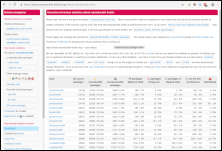

 Here is my monthly update covering what I have been doing in the free software world during April 2020 (
Here is my monthly update covering what I have been doing in the free software world during April 2020 (




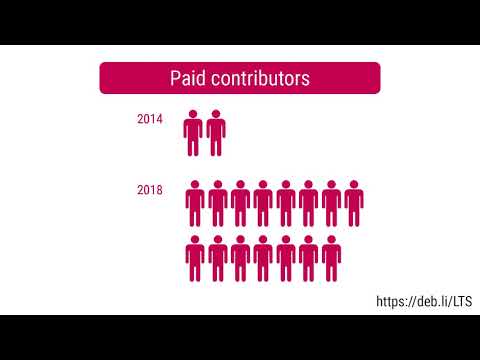


 How do you attract contributors to a new free software project?
I'm in the very early stages of a new personal project. It is
irrelevant for this blog post what the new project actually is.
Instead, I am thinking about the following question:
How do you attract contributors to a new free software project?
I'm in the very early stages of a new personal project. It is
irrelevant for this blog post what the new project actually is.
Instead, I am thinking about the following question:
 The
The